Biohazard & AI Corruption
“Entangled Magazine” April
autor: Kathleen&Anthony Patch (1.deo)
Naslovnica ovomesečnog izdanja Entangled Magazina je tamne boje, zlokobno u svom predznaku zla, predstavlja sadašnje stanje tame koja se nadvija nad skraćenom budućnošću čovečanstva i krajnjim postojanjem.
Lobanja i kosti, simbol smrti, zajedno sa međunarodnim crvenim simbolom BIOHAZARD, upozoravaju na egzistencijalnu pretnju koju predstavljaju korumpirani “podaci” (data).
Kao izvor života sveprisutnog globalnog računarstva, baze podataka doživljavaju povećanu kontaminaciju iz spoljnih izvora. Trenutno postoji direktna korelacija između baza podataka i biologije s obzirom da su obe podložne kontaminaciji i korupciji. Danas su biološki sistemi i njihove operacije predstavljeni u obliku digitalnih podataka. Dakle, integritet takvih podataka odgovara stanju bioloških sistema.
Kontaminacija podataka negativno utiče na integritet genomskih baza podataka i derivatne terapije zasnovane na genima, što dovodi do smrtonosnih posledica po ljudsku populaciju.
Počevši od uvoda u veštačku inteligenciju i baze podataka koje se koriste kao modeli obuke za ove sisteme, demonstriramo kako na računare negativno utiče gubitak integriteta baze podataka. Zatim ispitujemo kontaminaciju koja se nalazi u bazama podataka GeneBank i posledice koje proizilaze po današnje zdravstvene sisteme na koje sve više utiče i usmerava veštačka inteligencija.
Generativna AI (Generative AI) je široka kategorija za tip veštačke inteligencije koja može da generiše nove podatke, kao što su audio, fotografije, video i tekst.
Funkcija generisanja teksta Generativne AI je izgrađena na osnovnim AI modelima, kao što su modeli velikih jezika – Large Language Models (LLM).
Ovi LLM su konstruisani korišćenjem milijardi parametara (varijabli koje model uči tokom obuke) posebno za proizvodnju teksta.
Veliki jezički modeli (LLM) koriste velike skupove podataka i tehnike dubokog učenja- Deep Learning (DL) za generisanje i predviđanje novog sadržaja zasnovanog na tekstu.
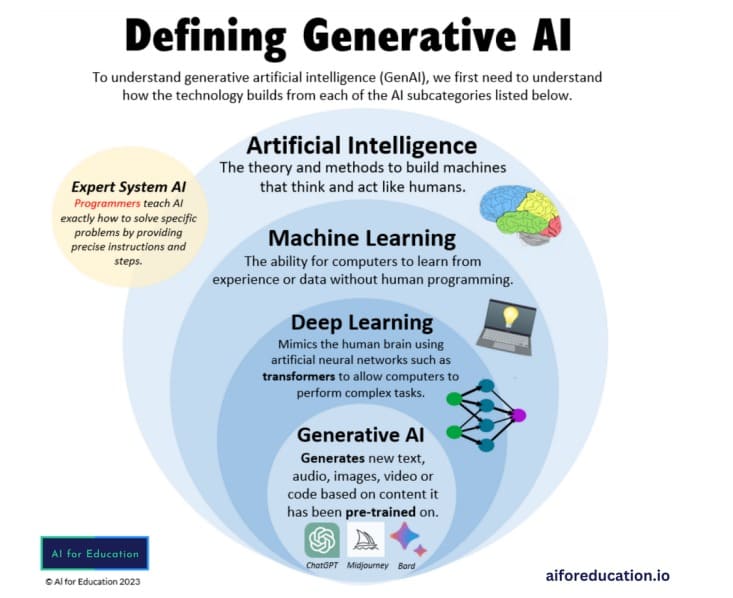
Deep Learning je vrsta Machine Learning – mašinskog učenja i veštačke inteligencije koja imitira način na koji ljudi uče.
Modeli Deep Learning obučavaju AI za obavljanje zadataka klasifikacije i prepoznavanje obrazaca u audio, nepokretnim slikama, video i tekstualnim podacima. Ovi modeli obuke se oslanjaju na velike skupove podataka označenih ljudi (Human-labeled data) raspoređenih u arhitekturi neuronskih mreža.

Sastoje se od više slojeva softverskih čvorova, veštačke neuronske mreže – Artificial Neural Networks (ANNs) imitiraju milione međusobno povezanih neurona unutar ljudskog mozga. Ovi čvorovi olakšavaju obuku modela dubokog učenja koji tada rade kao DL programi. Ovi višestruki slojevi obrade međusobno povezanih čvorova prečišćavaju i optimizuju klasifikacije i predviđanja.
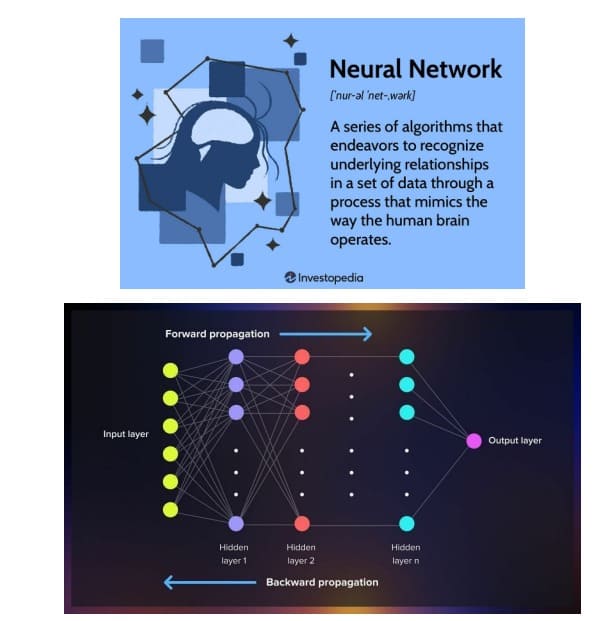
Deep referenca u Deep Learning odražava količinu slojeva obrade kroz koje prolaze podaci unutar arhitekture veštačke neuronske mreže. Veliki jezički modeli dubokog učenja (DL) sprovode nelinearne transformacije svojih ulaznih podataka, što rezultira izlazom novog statističkog modela.
Linearnost se odnosi na svojstvo sistema ili modela gde je izlaz direktno proporcionalan ulazu, dok nelinearnost implicira da je odnos između ulaza i izlaza složeniji i ne može se izraziti kao jednostavna linearna funkcija.
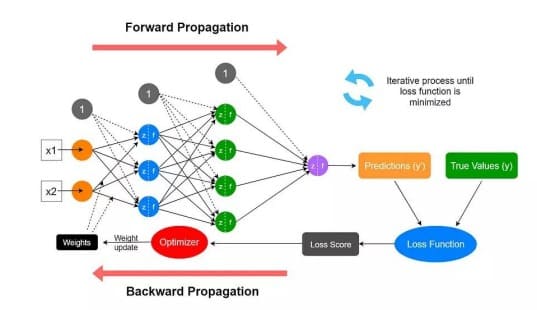
Large Language Models (Veliki jezički modeli) u velikoj meri predstavljaju klasu arhitekture dubokog učenja koje se nazivaju Transformer Networks (transformatorske mreže). Model transformatora je neuronska mreža koja uči kontekst i značenje praćenjem odnosa u sekvencijalnim podacima, kao što su reči u ovoj rečenici.

Transformator se sastoji od više blokova transformatora, poznatih i kao slojevi (layers). Na primer, transformator ima slojeve samopažnje, napredne slojeve i normalizovane slojeve, koji svi zajedno rade na dešifrovanju ulaza za predviđanje tokova izlaza pri zaključivanju. Slojevi se mogu slagati kako bi se napravili dublji transformatori i moćni jezički modeli.

Proces izdavanja novog statističkog modela, koji se naziva iteracija (ponavljanje koraka), traje sve dok izlazni model ne postigne unapred određen nivo tačnosti. Podaci o obuci se dostavljaju programu za duboko učenje (DL) za proizvodnju skupa funkcija kao što je statična slika. Kroz iteracije ovih podataka za obuku, DL program će konstruisati prediktivni model nepokretne slike na osnovu obrazaca piksela u podacima. Tačnost statističkog modela se povećava sa svakom uzastopnom iteracijom podataka u obuci.
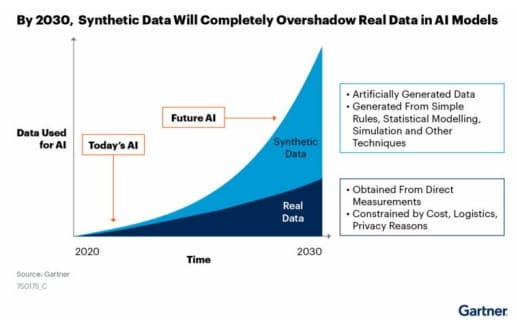
Tačnost statističkog modela zavisi od kvaliteta i kvantiteta podataka u obuci (training data) i pristupa dovoljnoj računarskoj moći. Ovi podaci o obuci uključuju velike količine neoznačenih, nestrukturiranih i sintetičkih podataka.
Synthetic data (sintetički podaci) su informacije koje su veštački generisane, a ne proizvedene događajima u stvarnom svetu.
Obično kreirani pomoću algoritama, sintetički podaci se mogu primeniti za validaciju matematičkih modela i za obuku modela mašinskog učenja.
Podaci generisani kompjuterskom simulacijom mogu se posmatrati kao sintetički podaci.
Istorijski gledano, proces mašinskog učenja je bio nadziran od programera. Ovo je uključivalo davanje specifičnih instrukcija računaru za identifikaciju karakteristika (koji se nazivaju ekstrakcija karakteristika) jedinstvenih za objekat ili sliku. Danas ljudi više nisu potrebni.
Programi dubokog učenja bez nadzora (Unsupervised Deep Learning) su sposobni da raspoređuju funkcije (training data) u skupove. Unutar ovih skupova, računar traži i identifikuje obrasce piksela. S druge strane, obrasci se koriste kao modeli obuke, što rezultira statistički prediktivnim modelima.
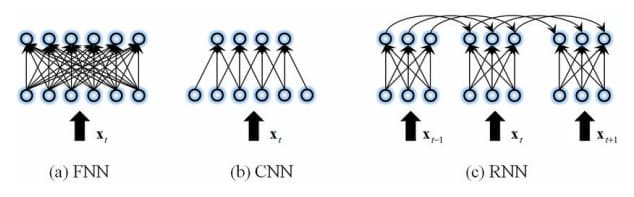
Sa pojavom big data i cloud-a, programi dubokog učenja proizvode prediktivne modele obuke direktno iz iterativnog izlaza programa i sastoje se od velikih količina neoznačenih i nestrukturiranih podataka. Jedan od naprednijih programa za duboko učenje naziva se veštačka neuronska mreža. Mreža se sastoji od ulaznih, skrivenih slojeva, izlaznih slojeva i čvorova. Čvorovi funkcionišu kao slojevi čuvara mesta za ulazne podatke, dok izlazne mreže zavise od broja čvorova i slojeva. Skriveni slojevi su više slojeva koji obrađuju podatke koji se šalju dodatnim slojevima unutar Artificial Neural Network (ANN). Pored tipa ANN, postoje rekurentne – Recurrent (RNN), konvolucione – Convolutional (CNN) i napredne neuronske mreže- Forward Neural Networks (FNN).