Analitika (Big data) velikih podataka uključuje velike količine podataka koje obrađuju napredni računarski sistemi. U početku su podaci o obuci označeni, za razliku od neobeleženih i nestrukturiranih podataka koji su od male koristi u izgradnji modela obuke. Jednom obučeni, programi Deep Learning (duboko ucenje) mogu napredovati korišćenjem modela obuke koji se sastoje od označenih podataka.

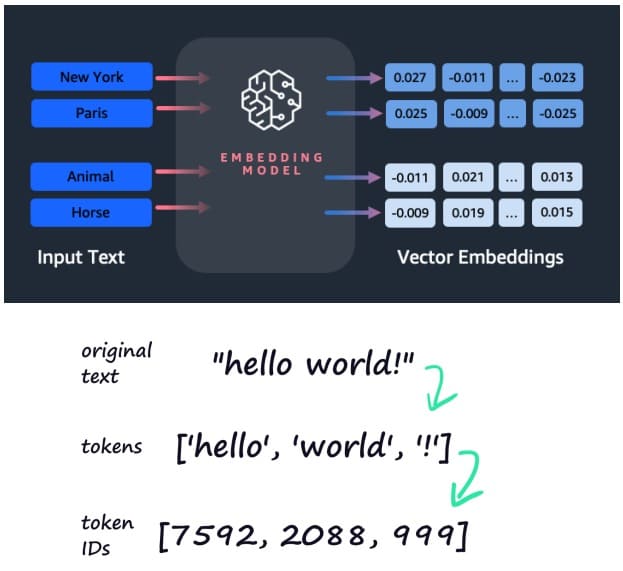
Danas su primarni primer arhitekture dubokog učenja (DL) transformatori, vrsta neuronske mreže, koja menja (input) ulaznu sekvencu u (output) izlaznu sekvencu. Ovo uključuje pretvaranje teksta u numeričke reprezentacije koje se nazivaju tokeni, koji se zatim pretvaraju u vektor. Svaki token je kontekstualizovan u okviru kontekstnog prozora.
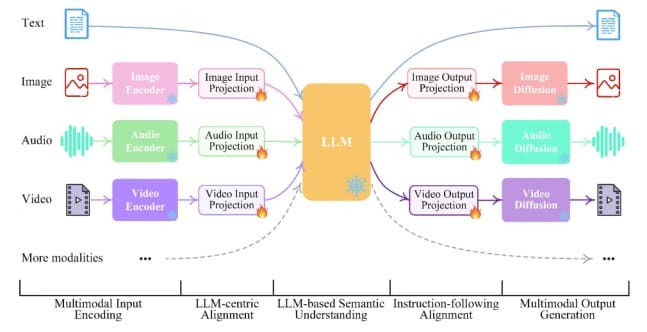
Počevši od 2017. godine, transformatorski modeli (transformatori) doveli su do razvoja modernih modela velikih jezika (Large Language Models- LLM) kao što su ChatGTP, Bard, Bing, itd. I dalje unutar šire kategorije generativne AI, ovi LLM-ovi su u stanju da obrađuju zvuk, slike, itd. kao multimodalni unos za razliku od jednostavnog teksta .
Kompanija OpenAI je 2022. godine prvi put objavila Chat GPT-3 (GPT =Generative Pre-trained Transformer) sa unosima samo za tekst. Trenutno, najnovija verzija, GPT-4 je sposoban da obrađuje ove multimodalne ulaze, dok uključuje preko 175 milijardi parametara (promenljivih).
Transformator se sastoji od višestrukih transformatorskih blokova, koji se nazivaju slojevima, uključujući slojeve normalizacije, slojeve za napredovanje i slojeve samopažnje. Oni funkcionišu unisono za dekodiranje ulaza kako bi se predvideo (zaključujući) izlaz. Slojevi se zatim slažu, što rezultira dubljim transformatorima i sposobnijim jezičkim modelima.
Generativni AI modeli velikih jezika (LLM) se obučavaju na setovima podataka, a program zaključuje (Inference) odnose između reči i slika. LLM je tada u stanju da proizvede novi sadržaj na osnovu ovih skupova podataka. Zaključak o novom sadržaju zasniva se na kvalitetu i kvantitetu (preko jedne milijarde) parametara (varijabli) uključenih u LLM.
Large Language Models predstavljaju temeljne modele, termin koji je prvi put upotrebio Stenfordski institut za veštačku inteligenciju usmerenu na čoveka 2021. Oni služe kao osnova za napredne optimizacije i specijalizovane aplikacije.

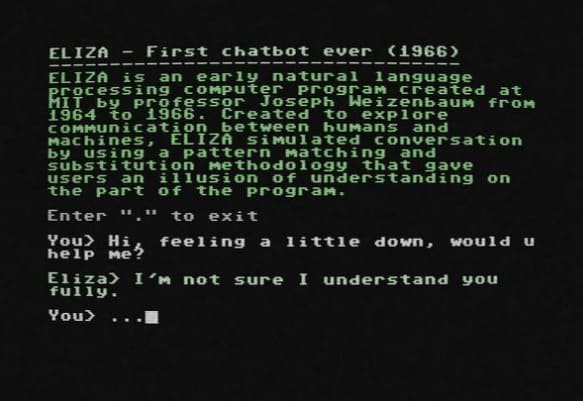
Prethodnik ovih velikih jezičkih modela (LLM) bio je rani program za obradu prirodnog jezika (NLP) koji je njegov programer Džozef Vajzenbaum 1964. na MIT-u dao ime ELIZA. Program je simulirao razgovor sa čovekom primenom metodologije podudaranja i zamene šablona. Međutim, sistem se oslanjao na ljudsko uređivanje svoje aktivne skripte da bi promenio način na koji će program raditi.
Današnji LLM-i su obučeni za stotine milijardi parametara koji su indeksirani i izvučeni iz skupova podataka na Internetu, što rezultira generisanjem sadržaja nalik ljudima. Ova obuka predstavlja učenje bez nadzora, u kojem su modeli u stanju da otkriju nepoznate obrasce u podacima koristeći neobeležene skupove podataka, čime se eliminiše potreba za označavanjem ljudskih podataka. Ovo rezultira LLM-ovima koji se zatim mogu koristiti u različitim aplikacijama i stoga se nazivaju osnovnim modelima.
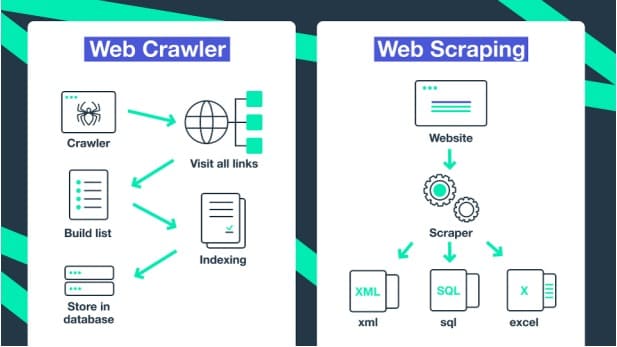
Ovi osnovni modeli LLM su obučeni na petabajtima podataka, koji se pominju kao korpus i zahtevaju više koraka. Oni počinju učenjem bez nadzora korišćenjem nestrukturiranih i neoznačenih podataka, što rezultira modelom koji određuje kontekst reči i koncepte.
Large Language Models se fino podešavaju kroz samokontrolisano učenje, stičući razumevanje reči i koncepata zasnovano na mašinama. Računar to radi tako što koristi mehanizam samopažnje, sistem bodovanja koji se sastoji od dodele težine datom tokenu.
LLM temeljni model zatim obrađuje identifikaciju odnosa unutar obrazaca podataka.
Opasnosti od neispravnih podataka u veštačkoj inteligenciji i biologiji
Kada je LLM obučen do željenog nivoa, može se ispitivati korišćenjem upitnika koje generiše čovek (tekstualni ili glasovni) korišćenjem aplikacija za obradu prirodnog jezika (NLP- Natural Language Processing). Izvlačeći zaključke iz prethodnih podataka o obuci, LLM onda daje odgovor.
Ovi odgovori su zasnovani na predviđanjima koja se sastoje od malog broja unosa ili upita. Ovi unapred obučeni LLM-ovi se zatim mogu koristiti kao generativna AI za izlaz sadržaja iz inputa na osnovu obrade prirodnog jezika (NLP).
Kako se osnovni modeli modela velikog jezika povećavaju u količini i karakteristikama, tako se povećava i oštećenje podataka.
Pozivan kao Model Collapse, opseg oštećenja podataka odgovara ubrzanoj stopi kojom se LLM obučavaju na korpusu (petabajta) podataka.

Početni modeli obuke za LLM su napravljeni korišćenjem podataka koje generiše čovek. Naknadni modeli zatim uključuju sintetičke podatke generisane od strane drugih LLM-ova koji mogu izazvati promenu distribucije koja rezultira kolapsom modela. Da bi se sprečio takav događaj, modeli obuke treba da imaju pristup originalnim bazama podataka, uključujući podatke koje nisu proizveli drugi LLM.
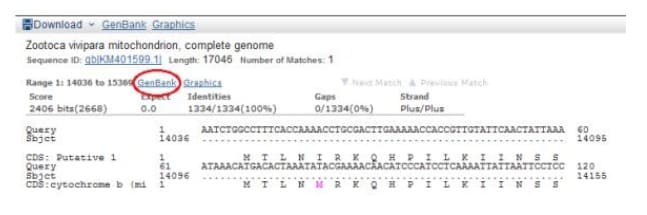
Veliki jezički modeli (LLM) su primarni primer arhitekture dubokog učenja (DL) koja uključuje obuku veštačke neuronske mreže (ANN). Sa više slojeva zasnovanih na velikim skupovima podataka obeleženih podataka, ANN je primenjen na analizu genetskih podataka izvedenih iz biobanke (tj. GenBank, itd.) DNK i RNK.
Zbog količine i složenosti bioloških podataka, prediktivni modeli bioloških sistema su morali da se konstruišu u okviru arhitektura dubokog učenja.
AI dubokog učenja (DL) je izgrađen od osnovnog mašinskog učenja (ML) algoritma, i nadgledani i nenadgledani, od kojih je svaki specifičan za zadatak. Modeli obuke su izgrađeni od primera koji se sastoje od ulaznih podataka i izlaznih oznaka. Izlazni podaci se zasnivaju na prepoznavanju obrazaca unutar ulaznih podataka, koji se zatim označavaju od strane Deep Learning AI sistema.
Iz ovih obrazaca, računar daje predviđanje, koje u slučaju genomike može biti sledeći nukleotid baznog para u nizu, ili lokacija specifičnog gena unutar celokupne genomske sekvence. Ovaj proces prepoznavanja obrazaca zavisi od integriteta sekvenci gena i nukleotida baznih parova koji se nalaze u genomskim bazama podataka. Nedostatak integriteta dovodi do pojave korupcije podataka i srodne proizvodnje terapeutika zasnovanih na genima. Svaka korupcija u genetskim podacima ima smrtonosne posledice za ljudsku populaciju.